Publications

ManiSkill3: GPU Parallelized Robotics Simulation and Rendering for Generalizable Embodied AI
arXiv
PDF Project Code
ManiSkill3 is an open-source, GPU-parallelized robotics simulator focusing on generalizable manipulation with contact-rich physics. It supports GPU parallelized simulation+rendering, heterogeneous simulation, and more via a simple object oriented API. ManiSkill3’s high-speed simulation and efficient rendering (30,000+ FPS), performs 10-1000x faster and uses 2-3x less GPU memory than competitors. The platform covers 12 diverse task domains including humanoids, mobile manipulation, and drawing. It provides realistic scenes and millions of demonstration frames. ManiSkill3 also includes comprehensive baselines for RL and learning-from-demonstrations algorithms.

NeuManifold: Neural Watertight Manifold Reconstruction with Efficient and High-Quality Rendering Support
Winter Conference on Applications of Computer Vision (WACV) 2025
PDF Project Video
We present a method for generating high-quality watertight manifold meshes from multi-view input images. Existing volumetric rendering methods are robust in optimization but tend to generate noisy meshes with poor topology. Differentiable rasterization-based methods can generate high-quality meshes but are sensitive to initialization. Our method combines the benefits of both worlds; we take the geometry initialization obtained from neural volumetric fields, and further optimize the geometry as well as a compact neural texture representation with differentiable rasterizers. Through extensive experiments, we demonstrate that our method can generate accurate mesh reconstructions with faithful appearance that are comparable to previous volume rendering methods while being an order of magnitude faster in rendering. We also show that our generated mesh and neural texture reconstruction is compatible with existing graphics pipelines and enables downstream 3D applications such as simulation.
General-Purpose Sim2Real Protocol for Learning Contact-Rich Manipulation With Marker-Based Visuotactile Sensors
IEEE Transactions on Robotics (T-RO) 2024
PDF Website
We build a general-purpose Sim2Real protocol for manipulation policy learning with marker-based visuotactile sensors. To improve the simulation fidelity, we employ an FEM-based physics simulator that can simulate the sensor deformation accurately and stably for arbitrary geometries. We further propose a novel tactile feature extraction network that directly processes the set of pixel coordinates of tactile sensor markers and a self-supervised pre-training strategy to improve the efficiency and generalizability of RL policies.

Part-Guided 3D RL for Sim2Real Articulated Object Manipulation
IEEE Robotics and Automation Letters (RA-L) 2023
PDF Code Video
We proposes a novel part-guided 3D RL framework, which can learn to manipulate articulated objects without demonstrations. We combine the strengths of 2D segmentation and 3D RL to improve the efficiency of RL policy training. Frame-consistent Uncertainty-aware Sampling (FUS) strategy is designed to get a condensed and hierarchical 3D representation, improving the stability of the policy in reality. Futhermore, a single versatile RL policy can be trained on various tasks simultaneously in simulation and shows great generalizability to novel instances in both simulation and reality.

ManiSkill2: A Unified Benchmark for Generalizable Manipulation Skills
International Conference on Learning Representations (ICLR) 2023
PDF Challenge Project Code
ManiSkill2 is a unified benchmark for learning generalizable robotic manipulation skills powered by SAPIEN. It features 20 out-of-box task families with 2000+ diverse object models and 4M+ demonstration frames. Moreover, it empowers fast visual input learning algorithms so that a CNN-based policy can collect samples at about 2000 FPS with 1 GPU and 16 processes on a workstation. The benchmark can be used to study a wide range of algorithms: 2D & 3D vision-based reinforcement learning, imitation learning, sense-plan-act, etc.

Close the Optical Sensing Domain Gap by Physics-Grounded Active Stereo Sensor Simulation
T-RO 2023
PDF Project Doc
SAPIEN Realistic depth lowers the sim-to-real gap of simulated depth and real active stereovision depth sensors, by designing a fully physics-grounded pipeline. Perception and RL methods trained in simulation can transfer well to the real world without any fine-tuning. It can also estimate the algorithm performance in the real world, largely reducing human effort of algorithm evaluation.

ManiSkill: Learning-from-Demonstrations Benchmark for Generalizable Manipulation Skills
NeurIPS 2021 Datasets and Benchmarks Track
PDF Challenge Video Code
Learning to manipulate unseen objects from 3D visual inputs is crucial for robots to achieve task automation. See how we build the SAPIEN Manipulation Skill Benchmark and collect many demonstrations without human labelling. ManiSkill supports object-level variations by utilizing a rich and diverse set of articulated objects, and each task is carefully designed for learning manipulations on a single category of objects.

OCRTOC: A Cloud-Based Competition and Benchmark for Robotic Grasping and Manipulation
IEEE Robotics and Automation Letters (RA-L)
PDF Challenge
We propose a cloud-based benchmark for robotic grasping and manipulation, specifically table organization tasks. With the OCRTOC benchmark, we aim to lower the barrier of conducting reproducible research on robotic grasping and accelerate progress in this field. Using this benchmark we held a competition in IROS 2020, and 59 teams took part in this competition worldwide.
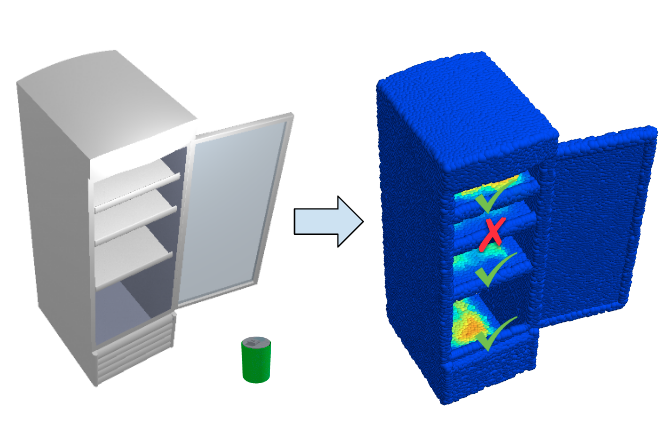
O2O-Afford: Annotation-Free Large-Scale Object-Object Affordance Learning
Conference on Robot Learning (CoRL) 2021
PDF Code
Contrary to the vast literature in studying agent-object interaction, very few past works have studied the task of object-object interaction, which also plays important role in downstream robotic manipulation and planning tasks. In this paper, we propose a large-scale annotation-free object-object affordance learning framework for diverse object-object interaction tasks.

MVSNeRF: Fast Generalizable Radiance Field Reconstruction from Multi-View Stereo
ICCV 2021
PDF Code
We present MVSNeRF, a novel neural rendering approach that can efficiently reconstruct neural radiance fields for view synthesis. Our approach leverages plane-swept cost volumes (widely used in multi-view stereo) for geometry-aware scene reasoning, and combines this with physically based volume rendering for neural radiance field reconstruction.

NeuTex: Neural Texture Mapping for Volumetric Neural Rendering
Conference on Computer Vision and Pattern Recognition (CVPR) 2021, Oral
PDF Project Website
We present an approach that explicitly disentangles geometry--represented as a continuous 3D volume--from appearance--represented as a continuous 2D texture map. We achieve this by introducing a 3D-to-2D texture mapping (or surface parameterization) network into volumetric representations.

SAPIEN: A SimulAted Part-based Interactive ENvironment
Conference on Computer Vision and Pattern Recognition (CVPR) 2020, Oral
PDF Code Project Website
We constructed a PhysX-based simulation environment using PartNet-Mobility dataset to support household robotics tasks. I am the project leader and worked on the following: 1. Constructed web interface for annotation of articulated object dataset. 2. Worked on a high-level simulator backed by PhysX. 3. Implemented OpenGL rasterization and OptiX ray-tracing for scene rendering. 4. Benchmarked motion prediction task with ResNet50/PointNet++ on RGB-D/point cloud inputs.